数据库水平扩容简述
随着云技术的不断发展,存储资源和计算资源的成熟,成本不断下降,使得企业开发部署提供服务更加的便捷。得益于此,对于高速发展的中小型企业,可以通过不断地堆砌机器,增加应用集群来应对不断增长的流量。
但是随着企业的不断发展,其中一个瓶颈并不能简单地通过堆砌机器来解决,这便是越来越庞大的数据库带来的性能天花。而应对这个天花板的有效手段之一,就是通过对数据库的分库分表,使得单表的数据量低于500W。
今天我们讨论一个更长远一点的问题。就是当企业进入了高速增长的赛道后,即便是对数据分库分表后,无论是数据库的容量,还是单库单表的数据量也总会到达天花板,此时该如何扩展我们的数据库性能。
分库分表这个概念十分好理解,就是原来存储在一个数据表内的数据,通过某种规则平均的分散在多个数据库的多张同样结构的数据表中。
我们假定以用户表(t_user)来举例子,假设当前这个表的数据量已经到达了2kw,相对500w这个临界值来说足足超过了4倍。那么我们如何通过分库分表来调整该表?
正如上面所说到的,我们可以对数据表其中一个或多个字段,通过某个可计算的平均的每次计算结果绝对一致的算法来分散存储我们的数据。可以很容易的想到很多种算法,比如对id进行mod运算,对创建时间按月分成多个表等等。
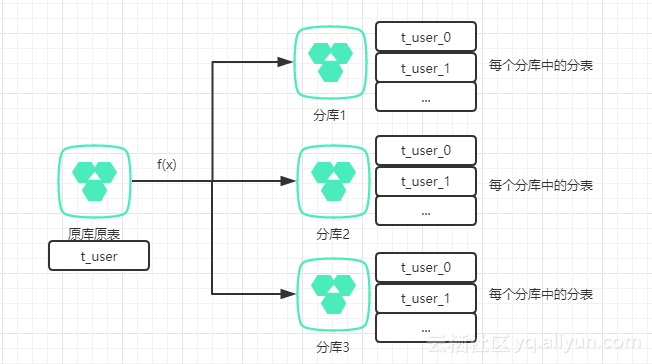
如上图所展示的,表通过函数fx的计算后倍分散到不同数据库的不同表中。这里可以简单代入一种分库算法——id取膜。
上图中一共分了三个数据库,每个库中又分了两张数据表。那么id % 3 == 0的数据都会集中到分库1中,分库1中的数据id % 2 == 0 的数据,又会存储在第一个分表中,其他如此类推。
首先来思考一下,水平扩展有什么技术难度?
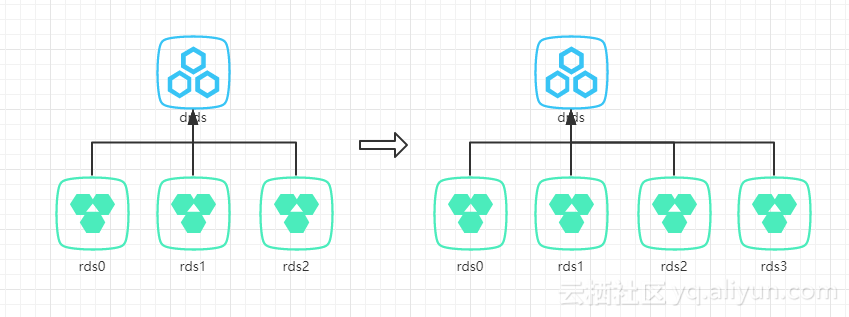
第一个显而易见的问题就是规则的变化和数据的迁移。
如果控制分库分表的规则是通过应用程序内完成的,规则的变化意味着必须重新发布使用新规则的应用集群。而数据迁移带来的麻烦则更加严重,在数据没有完成迁移之前,需要编写专门的脚本来处理数据的导出导入,不同的业务不同的表关系,都会使得这个脚本变得极其的复杂,而且还要同时兼顾增量数据同步,时间点,数据一致性等问题,稍有不慎,便会对用户的数据造成影响。
思考,是否有一种分库规则,在扩展分库的时候不需要进行规则的变化和数据的迁移呢?
答案当然是有的,就是将分库的规则修改为按段分库。如下图所示,如果我们分三个库,每个库中有两张分表(分表规则还是按取膜运算),那么一共可以存储3kw的数据,其中分库规则为id的值在[1,1kw]的会被存储到0库上,在[1kw+1, 2kw]范围的会被存储到1库,在[2kw+1, 3kw]范围的会被存储到2库。
当我们的数据量突破3kw时,我们只需要增加一个分库,用于存储[3kw+1, 4kw]范围的数据即可,完全不需要对前三个分库的数据做处理。同理,也可以基于时间的分库方式。
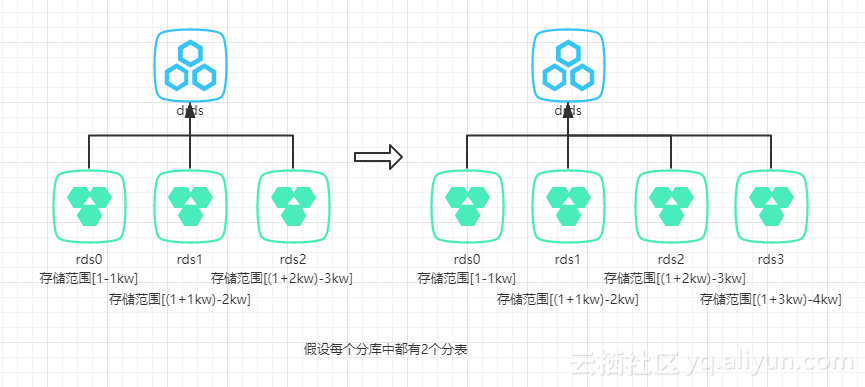 避免数据迁移和规则更新的分库示例图
避免数据迁移和规则更新的分库示例图
这种分库的规则优势可以说是非常的明显了,但是这种分库规则会带来什么样的劣势呢?
可以想象,我们为什么要做分库分表?就是单库的性能已经不能满足我们日常的业务需求了,需要将单个数据库的性能压力分摊到多个数据库上。而上述这种分库方式,势必会导致insert/update压力都集中到一个数据库实例上,并不能很好得分摊性能压力。
那么现在第三个问题来了,是否还有什么分库规划方式,既能避免数据迁移的成本,又能解决单库性能热点问题的方案呢?
答案肯定也是有的,下面我们来介绍一下阿里云TDDL团队给出的几种水平扩展模式。
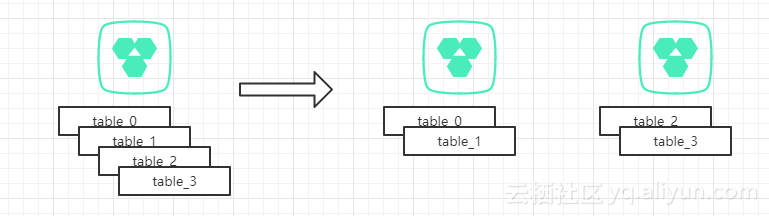
第一种水平扩展的模式如上图,在我们只有一个分库的时候,可以通过设定4个分表,示例中使用简单的id取膜分表方式。当单库的容量已经达到上限,我们可以通过增加一个数据库实例,把分表2,3整体迁移到新的实例上。
这样做的好处是,只需把整表迁移到新的库中即可,无需考虑单条数据因为规则的变化而重新计算需要迁移到那个库。当两个库也不够用是,以此类推,增加两个分库,分别吧table1和table3迁移到新的分库即可。
上述方案有一个缺点,就是在从一个库到4个库的过程中,单表的数据量一直在增长。当单表的数据量超过一定范围时,可能会带来性能问题。另外当开始预留的分表个数用尽,到了4物理库每库1个表的阶段,再进行扩容的话,不可避免的要再次从表上下手。
为了解决模式1的问题,我们接下来看看模式是如何处理的:
水平扩展模式2
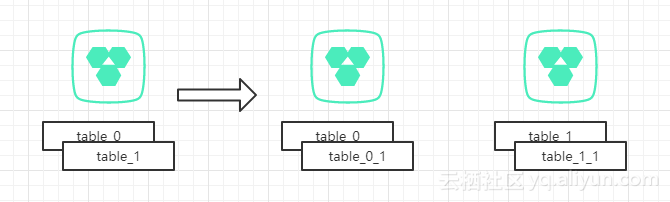
模式2与模式1有类似之处,在扩展阶段,还是选择整表迁移的方式,为了简化说明,此处使用两个分表来做说明。
如上图5,扩展了分库,把table1整表迁移到新库中后,如果此时单边已经快接近500w,我们可以在每个分库中再创建一个分表,用于存放超过500w部分的数据。此时分库分表的规则就变为:
通过id % 2确定分库,然后通过id段[1+0.5kw, 1kw]的数据分表存放在table_0_1和table_1_1中。这样既满足的降低单表500w水平线值,也解决了热点数据库的问题。
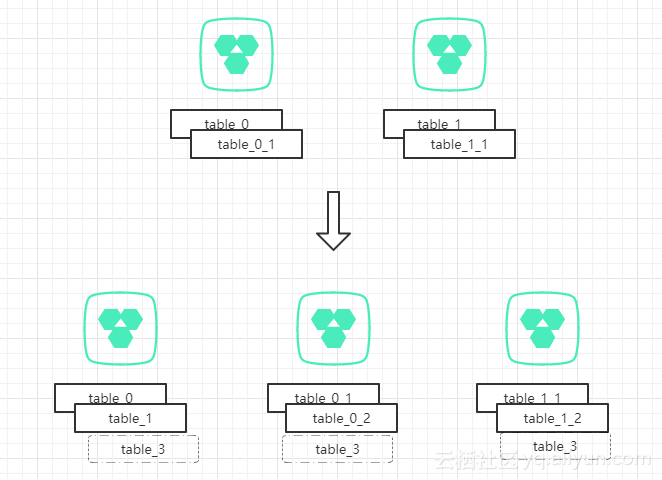
如果随着时间的流逝,我们的数据库容量需要再次升级,也只需要重新购买两个实例,把table_0_1和table_1_1分别迁移到新的实例上即可,同理也可以通过为每个分库建立新分表来解决500w问题。
以上都是倍数增长的扩容方案,对于中小型的企业来说,数据库资源的开销很是很大的。用2实例到4实例的费用就增长了一倍,而从4实例到8实例又增长了一倍。那么非倍数扩容的方案是如何的呢?
其实原理是相通的,譬如我们从2实例扩容到3实例时,此时我们table_0和table_1很大可能已经饱和了(单表达到500w),我们可以新购一个实例,用于存放这两个“历史数据”表,另外两个则按照模式2进行扩展,这样单库热点问题还是平均到两个库上。
当然,我们也可以通过给每个库增加一个分表,来达到每个分库都承担1/3的压力。只不过这种模式,对于分库分表的规则就提高和很大的复杂度。
水平扩展模式3
一个好的设计往往可以为后期的升级维护带来便利,数据库的水平扩容是一个很大的技术难点,但是通过优化我们的分库分表策,还是可以在一定程度上减轻工作量。这个准则无论是放到代码编写,产品设计或是生活的方方面面都一样适用,所以当我们遇到一个难以实现的设计时,也需要反思这种设计是否合理,是否会有更优的方案?
邮箱 626512443@qq.com
电话 18611320371(微信)
QQ群 235681453
Copyright © 2015-2024
备案号:京ICP备15003423号-3
