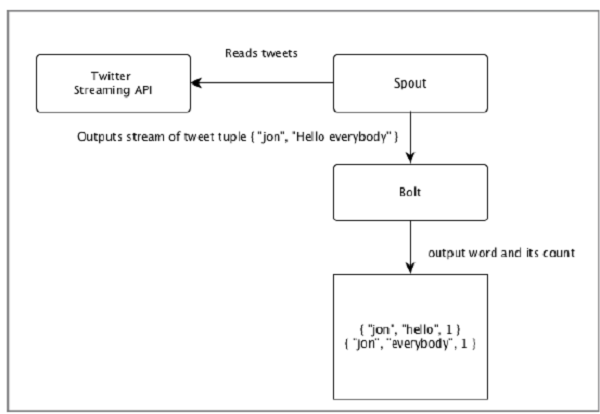
Apache Storm从一端读取实时数据的原始流,并将其传递通过一系列小处理单元,并在另一端输出处理/有用的信息。
下图描述了Apache Storm的核心概念。
现在让我们仔细看看Apache Storm的组件 -
| 组件 | 描述 |
|---|---|
| Tuple | Tuple是Storm中的主要数据结构。它是有序元素的列表。默认情况下,Tuple支持所有数据类型。通常,它被建模为一组逗号分隔的值,并传递到Storm集群。 |
| Stream | 流是元组的无序序列。 |
| Spouts | 流的源。通常,Storm从原始数据源(如Twitter Streaming API,Apache Kafka队列,Kestrel队列等)接受输入数据。否则,您可以编写spouts以从数据源读取数据。“ISpout”是实现spouts的核心接口,一些特定的接口是IRichSpout,BaseRichSpout,KafkaSpout等。 |
| Bolts | Bolts是逻辑处理单元。Spouts将数据传递到Bolts和Bolts过程,并产生新的输出流。Bolts可以执行过滤,聚合,加入,与数据源和数据库交互的操作。Bolts接收数据并发射到一个或多个Bolts。 “IBolt”是实现Bolts的核心接口。一些常见的接口是IRichBolt,IBasicBolt等。 |
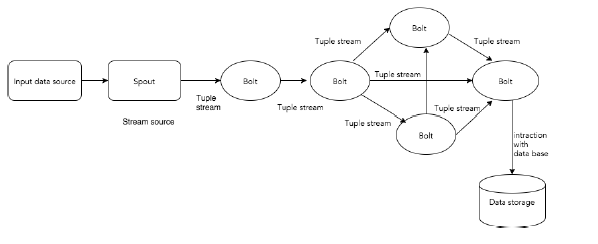
让我们来看一个“Twitter分析”的实时示例,看看如何在Apache Storm中建模。下图描述了结构。
“Twitter分析”的输入来自Twitter Streaming API。Spout将使用Twitter Streaming API读取用户的tweets,并作为元组流输出。来自spout的单个元组将具有twitter用户名和单个tweet作为逗号分隔值。然后,这个元组的蒸汽将被转发到Bolt,并且Bolt将tweet拆分成单个字,计算字数,并将信息保存到配置的数据源。现在,我们可以通过查询数据源轻松获得结果。
Spouts和Bolts连接在一起,形成拓扑结构。实时应用程序逻辑在Storm拓扑中指定。简单地说,拓扑是有向图,其中顶点是计算,边缘是数据流。
简单拓扑从spouts开始。Spouts将数据发射到一个或多个Bolts。Bolt表示拓扑中具有最小处理逻辑的节点,并且Bolts的输出可以发射到另一个Bolts作为输入。
Storm保持拓扑始终运行,直到您终止拓扑。Apache Storm的主要工作是运行拓扑,并在给定时间运行任意数量的拓扑。
现在你有一个关于Spouts和Bolts的基本想法。它们是拓扑的最小逻辑单元,并且使用单个Spout和Bolt阵列构建拓扑。应以特定顺序正确执行它们,以使拓扑成功运行。Storm执行的每个Spout和Bolt称为“任务”。简单来说,任务是Spouts或Bolts的执行。在给定时间,每个Spout和Bolt可以具有在多个单独的螺纹中运行的多个实例。
拓扑在多个工作节点上以分布式方式运行。Storm将所有工作节点上的任务均匀分布。工作节点的角色是监听作业,并在新作业到达时启动或停止进程。
数据流从Spouts流到Bolts,或从一个Bolts流到另一个Bolts。流分组控制元组在拓扑中的路由方式,并帮助我们了解拓扑中的元组流。有四个内置分组,如下所述。
在随机分组中,相等数量的元组随机分布在执行Bolts的所有工人中。下图描述了结构。
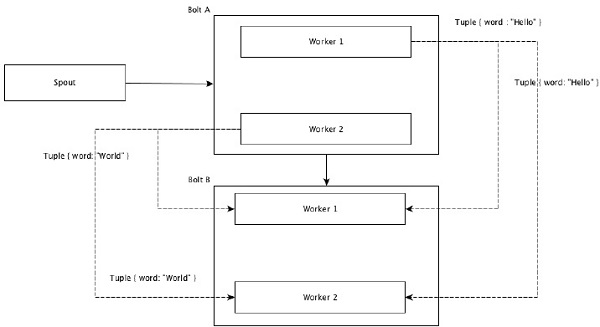
元组中具有相同值的字段组合在一起,其余的元组保存在外部。然后,具有相同字段值的元组被向前发送到执行Bolts的同一进程。例如,如果流由字段“字”分组,则具有相同字符串“Hello”的元组将移动到相同的工作者。下图显示了字段分组的工作原理。
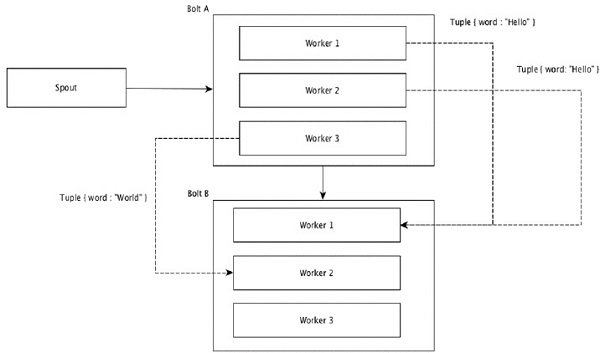
所有流可以分组并向前到一个Bolts。此分组将源的所有实例生成的元组发送到单个目标实例(具体来说,选择具有最低ID的工作程序)。
全局分组
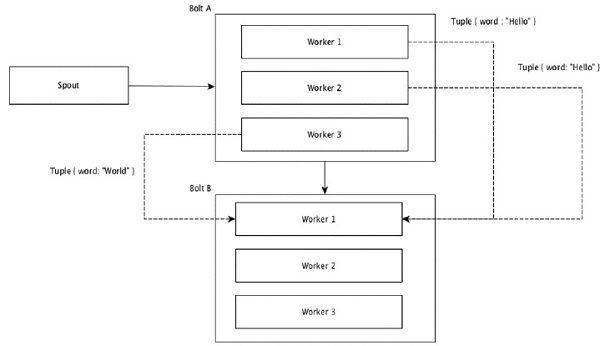
所有分组将每个元组的单个副本发送到接收Bolts的所有实例。这种分组用于向Bolts发送信号。所有分组对于连接操作都很有用。
所有分组
邮箱 626512443@qq.com
电话 18611320371(微信)
QQ群 235681453
Copyright © 2015-2024
备案号:京ICP备15003423号-3